【SEO】AIエージェント一覧とrobots.txt戦略
目次
こんにちは。
WebサイトをいかにAIサービスを介してアクセスを獲得できるかという点で、何の自動クローニングを許可するかを記載するrobots.txtの設定が重要であると考えます。 具体的には、「どのAIに、どこまでデータを渡すか」を定義する必要があります。
今回は、主要AIサービスの整理と、AIサービスからのアクセスを3用途に分け、用途ごとにSEOや流入にどう影響するかについて解説します。
そもそもrobot.txtとは
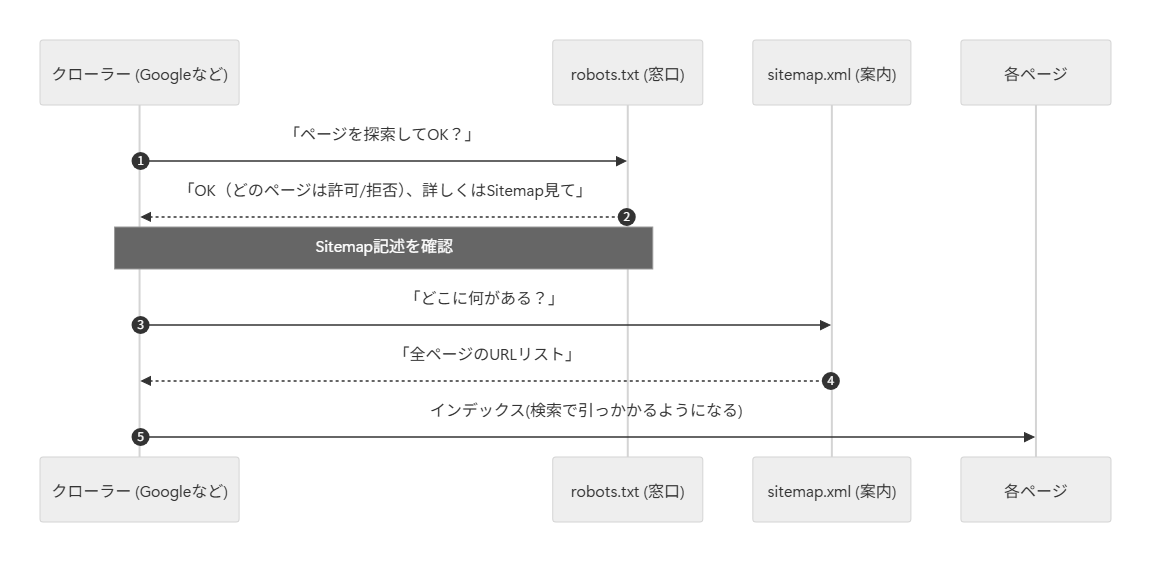
google等の検索エンジンとrobot.txt、sitemap.xmlの関係性を整理すると、役割が分かりやすくなります。
robot.txtおよびsitemap.xmlは、google検索結果にページが表示されるようになるインデックス化を行うために必要です。
- robot.txt:どのページを探索するのを許可/拒否するか、サイトマップの在処を記載
- sitemap.xml:どのページがどこにあるかを示す
robot.txtの例
サイトマップの例

robot.txtを記載するにあたり、「だれの」アクセスを許可するかという整理が非常に重要になります。
次のセクション以降、AIサービスからページにアクセスする目的だったり、どんなAIからアクセスを受けるかを整理しています。
AIエージェントからのアクセス「3パターン」
筆者としては、AIがサイトを訪れる目的は、大きく分けて3つのパターンに区別できると考えています。
3つの用途別にAIがサイトにアクセスする目的と、SEOへの影響を整理してみました。
| 用途 | アクセスの目的 | SEO・サイト流入への影響 |
|---|---|---|
| 検索用 | 質問に対し、Web検索を行って回答を生成する際にページにアクセス。回答内に出典URLが表示。 | その出典URLをクリックすることで、直接的な流入に直結。 |
| ユーザ用 | ユーザーが「この記事を要約して」と、特定のURLを貼り付けた際にページにアクセス。 | AIによるアクセスはカウント対象外となるが、記事の理解を助け拡散や再訪を促すため、間接的にはSEOへ寄与。 |
| 学習用 | チャット時の動作ではなく、裏側でのモデル学習用として使用するためにページにアクセス。 | 流入には繋がらない可能性が高い。 回答を機にユーザが再検索し来訪する望みはあるが、AIチャット内で完結し流入が減る可能性が高い。 |
主要AIサービス:User-agent 最新比較表
robot.txtは、User-agent ユーザエージェントと呼ばれるもので、「だれ」を判別します。
各社、目的ごとにUser-agentのリストを作成しました。
| 会社名 | エージェント名 (User-agent) | 用途 | 参照URL (ソース) |
|---|---|---|---|
| OpenAI | OAI-SearchBot | 検索用 | platform.openai.com |
| ChatGPT-User | ユーザ用 | platform.openai.com | |
| GPTBot | 学習用 | platform.openai.com | |
| Calude Code | Claude-SearchBot | 検索用 | support.claude.com |
| Claude-User | ユーザ用 | support.claude.com | |
| ClaudeBot | 学習用 | support.claude.com | |
| Googlebot | 検索用 | developers.google.com | |
| Google* (ワイルドカード) | ユーザ用 | developers.google.com | |
| Google-Extended | 学習用 | developers.google.com | |
| Perplexity | PerplexityBot | 検索用 | docs.perplexity.ai |
| Perplexity-User | ユーザ用 | docs.perplexity.ai | |
| Microsoft | bingbot | 検索用 | momenticmarketing.com |
| GitHub | 検索用としてbingbotを使用 | 検索用 | docs.github.com |
| Grok | ※他エージェント名によるステルス収集のため特定困難 | 検索/ユーザ/学習 | momenticmarketing.com |
※記載のないエージェントは情報が確認できませんでした。
AIエージェントを考慮したSEO対策:アクセスと知財のバランス
robots.txtを設定する際、 「検索用は必須で開ける、ユーザ用はなるべく、学習用は任意で」 という基本戦術となるかと思います。
攻めの運用(SEO重視)
SEOを重視するうえでは、AIによる回答内に参照URLを返すために「検索用」は必須です。 加えて、Webサイトに引き込む可能性を少しでも高めるために、ユーザが拡散・独自検索することも視野に入れ、「ユーザ・学習用」も許可することが重要だと考えます。
守りの運用(知財重視)
一方で、コンテンツを丸ごと吸収してしまう 「学習用」はゼロクリック検索を強める要因にもなり、組織によっては公開情報を汎用モデルに読み込ませたくない場合もあります。 その場合、「学習用」をブロックし、「検索用・ユーザ用」を許可するのをするのがいいと考えます。
robot.txt記載例
# --------------------------------------------------
# 【守りの運用】特定の学習用ボットのみ拒否し、他はすべて許可
# --------------------------------------------------
# 1. OpenAI学習用拒否
User-agent: GPTBot
Disallow: /
# 2. Claude学習用拒否
User-agent: ClaudeBot
Disallow: /
# 3. Google学習用拒否
User-agent: Google-Extended
Disallow: /
# 4. それ以外の検索用・ユーザ用を許可
User-agent: *
Allow: /
# サイトマップの指定
Sitemap: https://<mypage.com>/sitemap.xml
※攻めの運用の場合は、1~3の拒否を削除し、All Allowします。
おわりに
AIエージェントを考慮した、Robot.txtの記載方法について考察してきました。 Robot.txtの設定次第で、SEOに大きく影響してくるため、これを機に改めて設定を確認してみるのもいいかもしれません。
それでは。